
Observability has gained a lot of momentum and is now rightly a central component of the microservices landscape: It’s an important part of the cloud native world where you may have many microservices deployed on a production Kubernetes cluster, and a need to monitor these microservices keeps rising. In production, quickly finding failures and fixing them is crucial. As the name suggests, observability plays an important role in this failure discovery.
When we talk about the Kubernetes world there are many things to monitor and observe. In simple terms, we can classify three pillars of observability:
Metrics
Any data that can be aggregated can be counted as a metric. With more and more systems and applications, this becomes very important as it tells you how the application is performing over time, and moreover, how your system is performing. A simple example can be Prometheus that scrapes metrics from targets at regular intervals.
Tracing
This is important when we talk about microservices architecture as it gives insight into the applications running inside the Kubernetes cluster. Capturing traces of requests and determining what is happening throughout the request chain makes it easier to find issues such as bugs and causes of latency. Jaeger is a popular tool in this space.
Logs
Most likely, all of us have used log analysis at some point for debugging our applications, in order to get to the root of a problem. When we talk about a complex ecosystem like Kubernetes, where within the system itself there are many components that talk to each other in order to deploy an application, structured logging becomes very important. Tools such as Elastic, Loki and others are designed for logging such complex systems, where the volume of logs generated is larger and needs to be analysed and searched through quickly.
Now that we know the three pillars of observability it’s time to combine these, use the tooling available, and implement it on your infrastructure.
Depending on your deployment strategy and how you want to monitor your infrastructure, the combination of tools you’ll use to do this may vary.
Some of the different areas to consider observing while thinking about Kubernetes:
Kubernetes metrics
What should you measure and analyse? Kubernetes generates a lot of events and you should capture and store only the ones needed for a shorter period of time.
Latencies
Measure the latencies and connectivity between your application by tracing requests. This will help in defining service level objectives (SLO) as well.
Trends
The trends graph becomes very important when it comes to defining how the system and the application are behaving over the short and long term.
Long term storage
There will always be metrics that you may need for only for a day or two, and some you may need to keep on record for much longer periods of time, such as months and years. Always be mindful of long term storage solutions. Consider downsampling data to store fewer points long-term.
Structured logging
Not only do you need the right metrics, but also a structured method of logging with fast searches to help you debug any issues much quicker.
Alerting
All metrics should be tied to alerts, which should then fire when appropriate if something goes wrong.
Dashboards
Dashboards allow you to visualize the captured data to allow you to quickly derive actionable insights if needed.
Apart from the above, there can be specific areas/targets or application-level metrics that you may want to expose and capture. Based on your needs you can choose from various tools.
Example combinations
There are many possibilities when it comes to observability stacks. Here are just a few of the most widely used setups.
Prometheus + Thanos + Jaeger + Loki + Grafana
Prometheus + Cortex + Grafana
Prometheus + EFK stack
What you need and how much you want to scale will determine what you end up choosing for your stack. Traditionally you may build your stack from many of these tried and tested tools in combination, however, it is worth considering the rise in open source all-in-one observability platforms. These include:
SigNoz
SigNoz is a complete integrated platform for metrics, traces and logs which is both open source and easy to set up. It supports OpenTelemetry instrumentation and helps developers monitor their applications and troubleshoot problems. In simple terms, it can be thought of as an open-source alternative to commercial offerings such as DataDog, NewRelic, etc.
SigNoz supports two storage setups, one based on ClickHouse and another based on Kafka + Druid.
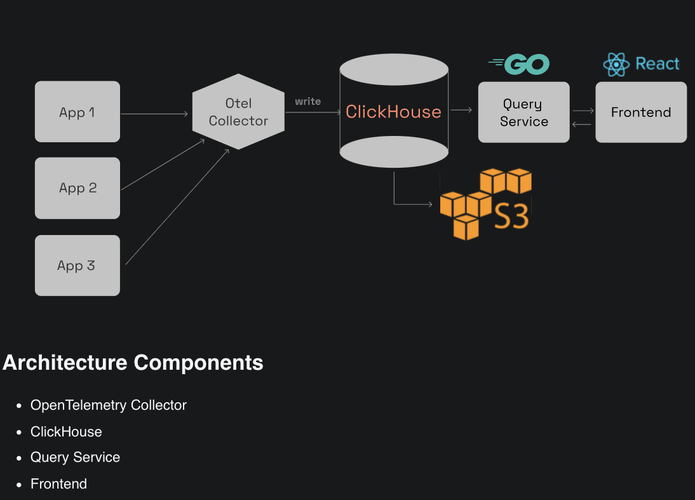
(https://github.com/SigNoz/signoz)
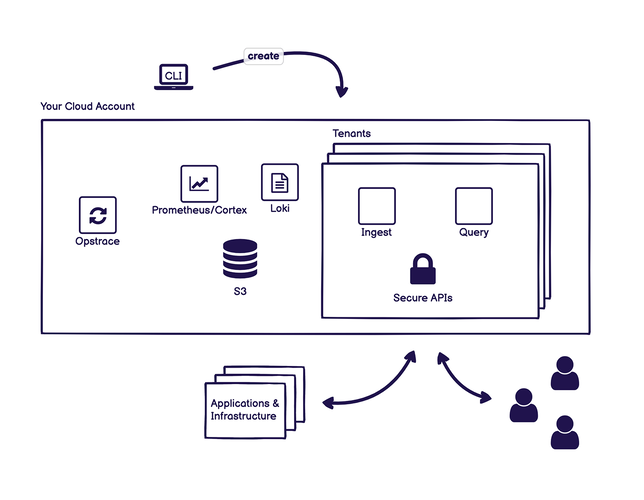
Opstrace
The Opstrace Distribution is a secure, horizontally-scalable, open source observability platform that you can install in your cloud account.
It uses open source tools, binding them together to create a complete solution. It exposes the Prometheus API backed by Cortex and uses Loki for log aggregation. You can also use your existing prometheus instances too.
(https://github.com/opstrace/opstrace)
AIOps (Artificial Intelligence Operations)
Another recent development within the observability space is AIOps (Artificial Intelligence Operations). Predicting failures before they actually happen is something we could all benefit from for our Kubernetes clusters. So, it is encouraging that there are tools being developed for anomaly detection even before one happens. One such tool is Opni.
Opni
Opni is a very new open source tool that helps with log anomaly detection for Kubernetes. You simply ingest logs to Opni and the built-in AI models will automatically learn and identify anomalous behaviour in your control plane, etcd, and applications logs.
Conclusion
The observability space will keep growing and we'll likely see many new tools emerge, especially complete observability platforms like SigNoz. This is because it can be challenging to choose the right set of tools initially and scale accordingly, so there is research that needs to be done for the tools over the metrics you have. Also, another space to watch out for is AIOps, which will likely only grow in the observability space in the near term.
Regardless of your choice of tools, the focus should always be to capture more metrics, and save only the right ones. If the data you are capturing helps you to find bugs and assists in fixing issues, you know you are benefiting from the solution you have chosen.
